Real-Time ASL Recognition Using 3D Convolutional Neural Networks

We don’t just build technology; we build on the shoulders of giants. Every line of code we write and every model we train is inspired by the seminal work of Danielle Bragg, Meredith Ringel Morris, and their colleagues from Microsoft, Gallaudet, RIT, and Maryland. Their 2020 paper, Sign Language Interfaces: Discussing the Field's Biggest Challenges, didn't just highlight a technical gap—it provided the ethical and structural compass we use today.
The Problem: More Than Just a Translation Gap
The original research team identified a systemic "Linguistic Wall." For the millions of primary signers worldwide, the digital world is essentially "silent" because it is built entirely on a text-centric foundation.
What we admire most about their insight is that they looked beyond the software. They pointed out that because American Sign Language (ASL) lacks a standard written form, it is often erased from data—even by official census metrics. This "invisibility" means that traditional search engines and AI models simply aren't built to "see" or index the spatial-visual richness of sign language.

The Core Idea: The Five Pillars of Equity
The original team moved the conversation away from "How do we make a cool gadget?" to "How do we create a sustainable ecosystem?" Their core idea was summarized in five transformative "Calls to Action" that we treat as our internal manifesto:
Nothing About Us Without Us: They insisted on partnering with the Deaf community to ensure cultural ownership.
Function Over Theory: They urged a shift toward real-world applications that solve immediate problems.
Standardized UI: They recognized that we need a common "language" for interfaces to avoid fragmented design.
Data Curation: They called for massive, diverse, and public datasets—the "fuel" for any AI.
Notation Standards: They identified the desperate need for a digital way to "write" signs for data labeling.
The Technical Evolution: Mastering Spatial-Temporal Volume
Inspired by these calls to action, our team has focused on solving the "Temporal Modeling" challenge mentioned in the research. We realized that sign language isn't a series of static poses; it is a volumetric dance of hands, body, and facial expression over time. To capture this, we’ve adopted and expanded upon the 3D CNN-LSTM hybrid architecture.
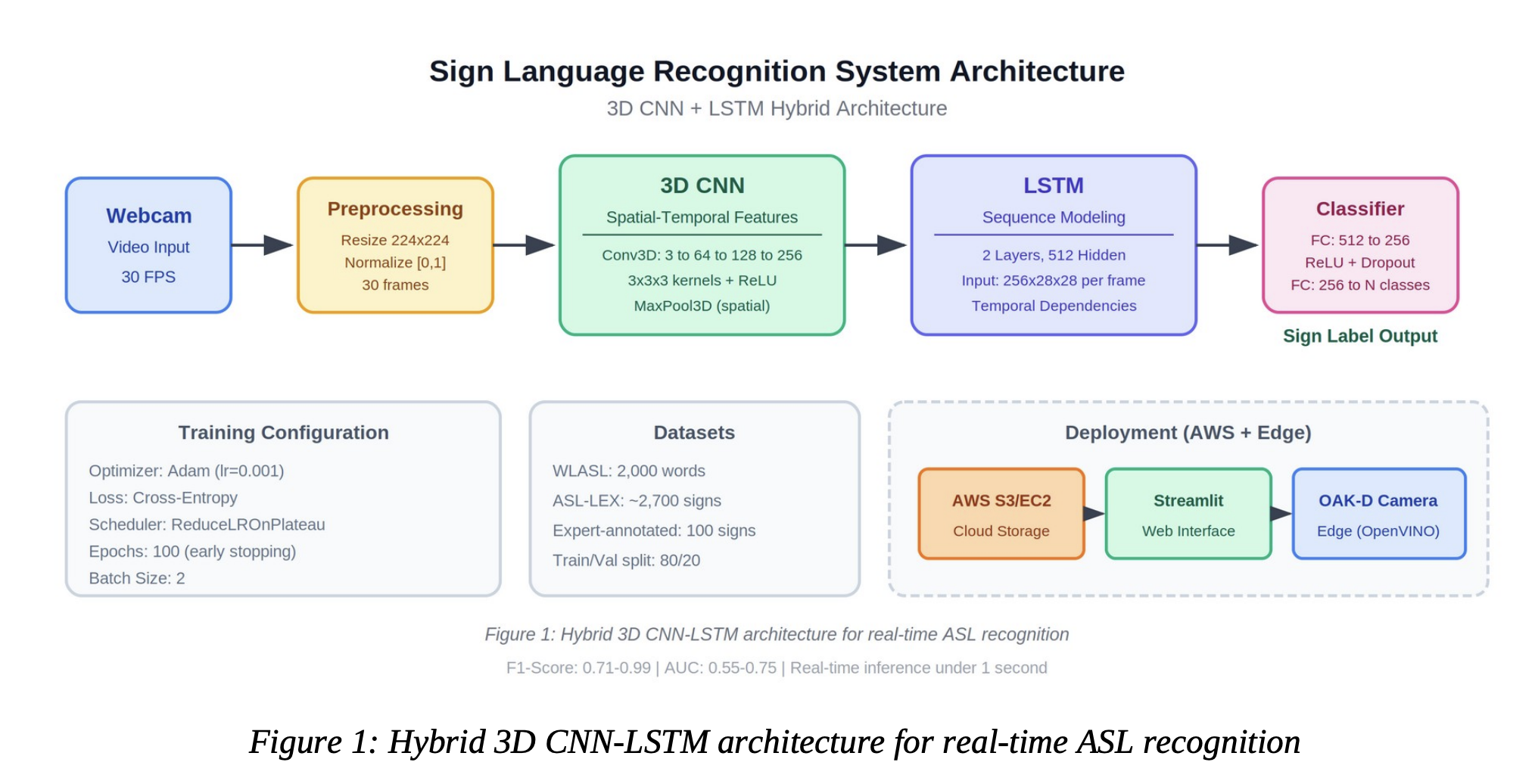
1. 3D Convolutional Neural Networks (3D CNN): The "Spatial Eyes". The Dawnena Key in his paper Real-Time American Sign Language Recognition Using 3D give a pathway to look to. While standard 2D AI looks at images frame-by-frame, 3D CNN approach processes video as a continuous block of data. By using 3D kernels (filters that move in three dimensions: height, width, and time), the system extracts "spatiotemporal" features. This means the AI isn't just seeing a "hand shape"; it is seeing the velocity and depth of that hand shape as it moves through the 3D space in front of the signer.
2. Long Short-Term Memory (LSTM): The "Sequential Brain" Capturing the motion is only half the battle. Sign language has a complex grammar where the order and duration of movements change the meaning entirely. Then you feed the features from the 3D CNN into an LSTM network. LSTMs are specialized at handling "long-term dependencies"—they remember what happened at the start of a sign to provide context for how it ends. This ensures that signs with similar starting positions but different endings are categorized with precision.
3. Training on Linguistic Truth Following the paper’s call for representative data, we don't just use "scraped" video. We train our models using the WLASL (Word-Level American Sign Language) dataset and the ASL-LEX lexical database. This ensures our AI understands the linguistic rules—such as handshape, location, and movement—defined by the community, leading to F1-scores as high as 0.99 in real-time environments.
Why This Research Matters for the Future
The original paper by Bragg et al. (2020) is essential because it proved that the "Sign Language Challenge" is not just a computer vision problem—it is a human-computer interaction (HCI) and social justice problem.
Their work paved the way for us to move recognition to "the edge." Because of their guidance, we are focusing on low-latency, on-device processing (using OAK-D cameras and OpenVINO) that respects user privacy and allows for natural, "head-up" communication.
We are moving forward with a deep sense of gratitude for the original research team. They defined the challenges; now, we are dedicated to building the solutions. We aren't just translating signs; we are honoring a culture and a language that has waited too long to be heard by the digital world.
References
Bragg, D., Morris, M. R., Vogler, C. P., Kushalnagar, R. S., Huenerfauth, M., & Kacorri, H. (2020). Sign Language Interfaces: Discussing the Field's Biggest Challenges. CHI Conference on Human Factors in Computing Systems (CHI EA '20).
Key, D. (2025). Real-Time American Sign Language Recognition Using 3D Convolutional Neural Networks and LSTM: Architecture, Training, and Deployment. University of Denver, M.S. Data Science.
Nature Scientific Reports (2025). Advancing sign language recognition with self-correction mechanism and multi-scale CNN-BiLSTM. Nature Portfolio.
Li, D., Rodriguez, C., Yu, X., & Li, H. (2020). Word-level Deep Sign Language Recognition from Video: A New Large-scale Dataset and Methods Comparison. WACV 2020.
Caselli, N. K., Sehyr, Z. S., Cohen-Goldberg, A. M., & Emmorey, K. (2017). ASL-LEX: A lexical database of American Sign Language. Behavior Research Methods, 49(2), 784-801.
Hochreiter, S., & Schmidhuber, J. (1997). Long Short-Term Memory. Neural Computation, 9(8), 1735-1780.